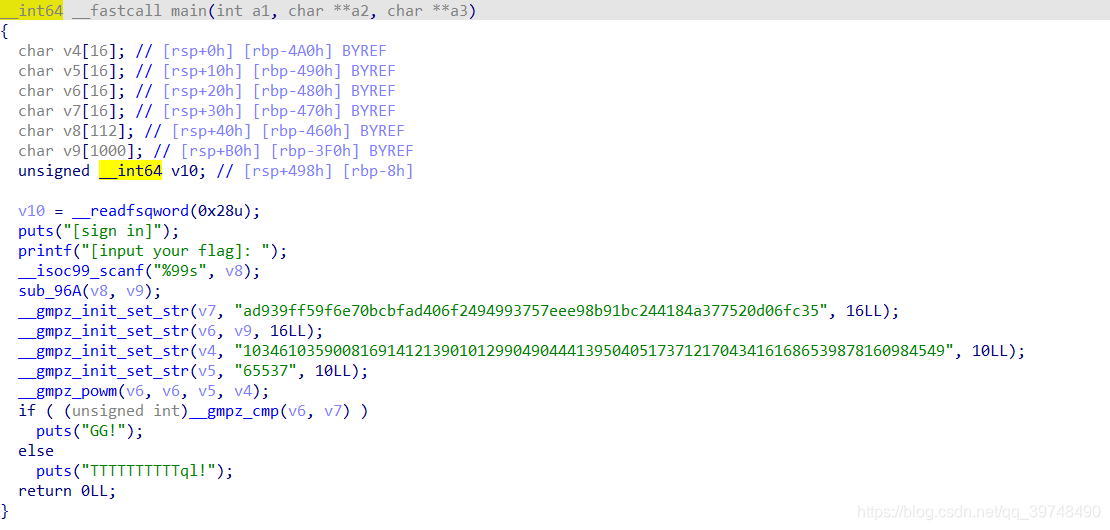
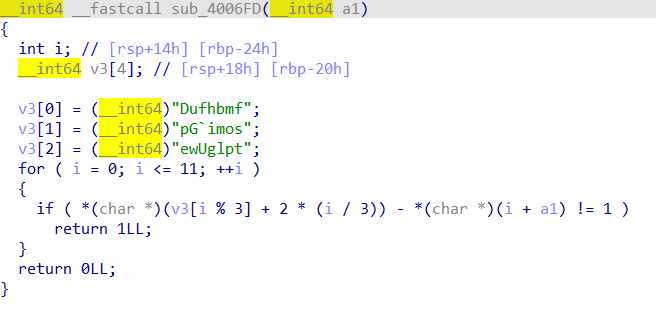
# let's provide the exact variables received through the scanf so we don't have to worry about parsing stdin into a bunch of ints. flag_chars = [claripy.BVS('flag_%d' % i, 32) for i in range(13)] class my_scanf(angr.SimProcedure): def run(self, fmt, ptr): # pylint: disable=arguments-differ,unused-argument self.state.mem[ptr].dword = flag_chars[self.state.globals['scanf_count']] self.state.globals['scanf_count'] += 1
sm = proj.factory.simulation_manager() sm.one_active.options.add(angr.options.LAZY_SOLVES) sm.one_active.globals['scanf_count'] = 0
# search for just before the printf("%c%c...") # If we get to 0x402941, "Wrong" is going to be printed out, so definitely avoid that. sm.explore(find=0x4028E9, avoid=0x402941)
# evaluate each of the flag chars against the constraints on the found state to construct the flag flag = ''.join(chr(sm.one_found.solver.eval(c)) for c in flag_chars) return flag
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header WORD e_magic; // Magic number WORD e_cblp; // Bytes on last page of file WORD e_cp; // Pages in file WORD e_crlc; // Relocations WORD e_cparhdr; // Size of header in paragraphs WORD e_minalloc; // Minimum extra paragraphs needed WORD e_maxalloc; // Maximum extra paragraphs needed WORD e_ss; // Initial (relative) SS value WORD e_sp; // Initial SP value WORD e_csum; // Checksum WORD e_ip; // Initial IP value WORD e_cs; // Initial (relative) CS value WORD e_lfarlc; // File address of relocation table WORD e_ovno; // Overlay number WORD e_res[4]; // Reserved words WORD e_oemid; // OEM identifier (for e_oeminfo) WORD e_oeminfo; // OEM information; e_oemid specific WORD e_res2[10]; // Reserved words LONG e_lfanew; // File address of new exe header } IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
(1)数据填充 填充消息使其长度与448模512同余,方法是附一个1在后面,然后用0填充。 (2)添加长度 附上64位消息长度,使之成为512的整数倍 (3)初始化变量(MD5Init()) 初始化A=0x01234567,B=0x89ABCDEF,C=0xFEDCBA98,D=0x76543210用来计算。 (4)数据处理(MD5Update()、MD5Final()) 主循环有四轮,每轮循环都很相似。第一轮进行16次操作。每次操作对a、b、c和d中的其中三个作一次非线性函数运算,然后将所得结果加上第四个变量,文本的一个子分组和一个常数。再将所得结果向左环移一个不定的数,并加上a、b、c或d中之一。最后用该结果取代a、b、c或d中之一。 以下是每次操作中用到的四个辅助函数(每轮一个)。 F( X ,Y ,Z ) = ( X & Y ) | ( (X) & Z ) G( X ,Y ,Z ) = ( X & Z ) | ( Y & (Z) ) H( X ,Y ,Z ) =X ^ Y ^ Z I( X ,Y ,Z ) =Y ^ ( X | (~Z) )